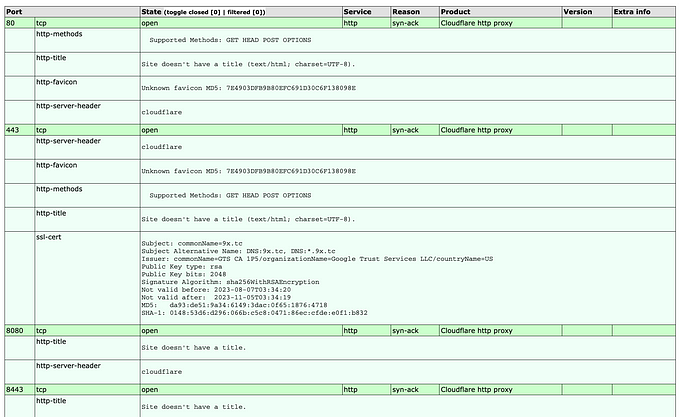
Verified list of 1000 random websites with sensitive keywords found in source: matched on “API| Secret| JWT| token|secret | AWS” : Goal : Iterate list (with curl?) identify leaked info — Why? sharpen skills and learn how not to code pages ;)! (10/23) (99% verified up) :

Verfied dump of the list of hosts cerified to have potnetial sensitive
info in the client side source:
[List on page *do not wgeT* ] https://pastes.io/uecpqskv8c
[wget link] https://9x.network/files/text/urlz_for_ethical_scraping_of_secrets.txt
Example of usage:
----------------
do this as a non root use - no need for root
mkdir secrets
wget https://9x.network/files/text/urlz_for_ethical_scraping_of_secrets.txt
mv urlz[tab] urls.txt
- lETS VERify that we have data in the list
bash$ head ./urls.txt # Remember? we renamed it
[ ************ top entries of file. you will notice alot of prominent sites ** ]
https://www.bbc.com/
https://slack.com/intl/en-gb/
https://www.gamespot.com/
https://www.businessinsider.com/?r=US&IR=T
https://www.hola.com/
https://www.orange.fr/portail
http://go.com/
https://www.nbcnews.com/
https://www.***.com/
https://www.vidio.com/categories/52-home-page
[ *************** [END OF HEAD STDOUT - Just verify the entitre list has no line
[ feeds OR dynam ic urls ]
bash$ which curl
/usr/bin/curl # Verify curl is ready
which xargs
/usr/bin/xargs
You might want to apt-get install html2text its very useful
try something like this if the list of 1000 urls in in urlz.txt
runme.sh:
----------------
#/bin/bash
cat urlz.txt | xargs -I{} sh -c "echo {};echo; curl -skL --connect-timeout 4 \
--user-agent 'mozzila' '{}'"
- AT this poit verify you can see the source being dumped. Im not going to
explain ow to grep and pattern match. good luck
You are looking at a List of 1000 of websites with high likely
hood of info exposureThese are the things I encounter most of the time:
potential api key in code or comments —
The comments are especially *easy to miss*
I have almost missed things in the client-side source comments that we
made the difference of me completing the pen test.
with that being said make a list of keywords to grep these sites for but you have to be good with
grep -v (display anything NOT matching) <keyword>
You can use grep on either the input side or piped thru to the output (both have various reasons for doing so. for example:
cat urlz.txt| grep -i ‘secret\|api’ # Note using “ vs ‘ in bash is much differen
The above will list out (initially to stdout) the URLs in urls.txt and check each “line’ (Which if the site is minified and we curl it, we get back 1000s of chars) on one line. making it very hard to spot anything good
Its worth assuming the code your viewing is generated by a CMS (WordPress, etc)
This unfortunately complicates things when trying to find keywords in
the source due to the fact that most CMS (Joomla and Drupal for sure)
are just JS files that are dynamo ically generating the page for your
client session DOM. In English, what this has meant in my dealings.
was heavy use of minification
*making sometimes a 2 million character script all on one line*
The main issue here is you need to do some regex foo to get just
the info you want typical greps arent going to work likely.
The *only* way i know how to deal w/minified 10mil long one liner scripts is using Xpath or XSLT (google them) — or another nifty method would be
using a PHP library called “simple_dom_html.php” (google it)
Without further ado, here is the list:
DISCLAIMER:
Dont do anything illegal with this information please -
*note: this is just how i would go about scraping these potentially **
cat urls.txt | xargs -I{} sh -e "echo {}"
Note what these developers (or who ever wrote the source your looking at )
Examine the structure and how the DOM is constructed as you start out
examining the list. Take it or leave it , this is my article and i
can rant about
what i want ;p
Q: Why did i bother posting this BS on medium ?
A: You could likely take over a extremely large % of these hosts
Q: What kinda info should i curl for ? - in specific
A: pick an interesting sounding name out of this list incognito visit the site
Once its loaded inspect element, then (in most browsers) hit CTRL T
(new tab) - hit the page:
** Def book mark for future use - get remote source of any page
** It is acting as a proxy so you get another prospective of the source.
Remote Source Code Viewer: [free]
https://www.view-page-source.com/
Next tasks to get the most of thi exercise (instead of just writing a script
that does a foreach adn greps for the keywo
Once it loads paste your link in and i usually pick stylize and hit go
Finally - it may seem pointing hbut hit C TRL T new tab
now v view the source on your local machine . Sometimes i have noticed (in Brave and Chrome)
I cannot find the selectiuon to "View Source"
If you only see inspect element, try right clikging outside any kind
of <canvas> or <svg> or video element, these prevent viewing of source.
Regardlkess of your role its you
this is simply for training
in red team exercises. If you are currently working at an org in an IT
security position you absolutely need to
contain keyword matches on: API|Secret|JWT|Bearer|token|sword|secret
examine all public facing webservers
and examine the following (this should take you like 4min by now to automate)
bash script t0
> curl -sLk --connect-timeout 3 'https://ibm.com/robots.txt' | grep -i disall
- I have found it *essential* to use the '--connect-timeout 3' in all my
automated headless browsing like this, you will def. run into non
responsive hosts.
YOU MAY BE ASKING (ABOUT THIS LIST):
_ _
| | | |
_ _ _| |__ _ _ __| | ___ _ _ _ _____
| | | | _ \| | | | / _ |/ _ \ | | | | ___ |
| | | | | | | |_| | ( (_| | |_| | | | | | ____|
\___/|_| |_|\__ | \____|\___/ \___/|_____)
(____/
___
/ _ \
____ _____ ____ ____(_( ) )
/ ___|____ |/ ___) ___ | (_/
( (___/ ___ | | | ____| _
\____)_____|_| |_____)(_)
---- You may wonder how this can help you reduce info exposure about your
company. Think about it this way - Index engines/Spiders/Crawlers/whatever
you call it do this for the reason of (most of the time) -
Identify content of site and category for listing in search\
Cache for viewing later on (like archive.org)
Check out grayhatwarfare.com - that is a search engine for insecure
s3 cloud buckets (all types) - the bottom line is check out what others
are doing *WRONG* - to be doing the best thing for your org - stay
ahead of your adversary by studying their activities stealthly but make
sure this is done over time . Lets get to the list:
https://github.com/
https://www.bbc.com/
https://slack.com/intl/en-gb/
https://www.gamespot.com/
https://www.businessinsider.com/?r=US&IR=T
https://www.hola.com/
https://www.orange.fr/portail
http://go.com/
https://www.nbcnews.com/
https://www.sex.com/
https://www.vidio.com/categories/52-home-page
https://www.news.com.au/
https://www.polygon.com/
https://ccm.net/
https://searchencrypt.com/
https://comicbook.com/
https://www.cbsnews.com/
https://www.instructables.com/
https://www.sbnation.com/
https://www.ted.com/
https://www.ranker.com/
https://om.forgeofempires.com/foe/en/?ref=dotcom
https://www.audible.com/
https://www.eporner.com/
https://metro.co.uk/
https://pngtree.com/
https://gnula.nu/
https://www.ubisoft.com/en-gb/
https://particuliers.societegenerale.fr/
http://worldlifestyle.com/
https://www.msnbc.com/
https://fitgirl-repacks.site/
https://www.ali213.net/
https://www.dek-d.com/
https://www.lamoda.ru/
https://www.ucsb.edu/
https://www.tsn.ca/
https://uproxx.com/
https://www.japantimes.co.jp/
https://www.thermofisher.com/uk/en/home.html
https://www.campograndenews.com.br/
https://dzone.com/
https://www.regions.com/personal-banking
https://www.governmentjobs.com/
https://myspace.com/
https://www.epicurious.com/
https://valemedia.net/
https://www.marksandspencer.com/
https://www.pcloud.com/eu
https://en.aptoide.com/
https://www.readworks.org/
https://www25.estrenosdoramas.net/
https://lingualeo.com/en
https://www.fark.com/
https://www.bancaribe.com.ve/
https://dotesports.com/
http://www.filmeserialeonline.org/home-fsonline-hd-14
https://www.nodepositbonus.cc/
https://www.travelandleisure.com/
https://infokosova.org/
https://www.marthastewart.com/
https://epn.bz/en/
https://www.newmobilelife.com/
https://www.ncrangola.com/loja/particulares/pt/
http://srvtrck.com/
https://www.washingtontimes.com/
https://www.film.ru/
https://www.meetic.fr/
https://www.gosunoob.com/
https://elwiki.net/w/Main_Page
https://www.dn.pt/
https://www.military.com/
https://www.men.com/
https://www.livetvcdn.net/
https://www.insee.fr/fr/accueil
https://www.infoq.com/
https://sendvid.com/
https://www.hottopic.com/homepage
https://www.instyle.com/
https://gizmodo.com.au/
https://vndb.org/
https://www.eventhubs.com/
https://www.camsoda.com/
https://www.domo.com/
https://washingtonpress.com/
https://teratail.com/
https://www.greatschools.org/
https://decider.com/
https://www.oreillyauto.com/
https://www.publishersweekly.com/
https://hitek.fr/
https://doujins.com/
https://www.princetonreview.com/
https://radaronline.com/
https://dilei.it/
https://www.warriorforum.com/
https://ziare.com/
https://in.via.com/
https://ftbwiki.org/Feed_The_Beast_Wiki
https://www.neliti.com/
https://www.metart.com/
https://www.secretescapes.com/
http://www.damplips.com/
https://coggle.it/
https://www.mediafax.ro/
https://www.ubergizmo.com/
https://www.novinhagostosa10.com/
https://www.tiffany.com/
https://www.kupindo.com/
https://www.gyldendal.dk/
http://www.jollychic.com/
http://weirduniverse.net/
https://sitenable.asia/
https://www.abcnyheter.no/
https://incompetech.com/
https://www.hermo.my/
https://www.democracynow.org/
https://www.bengo4.com/
https://milfzr.com/
https://tim.blog/
https://www.amc.com/
https://ideone.com/
https://www.ibtimes.com/
https://www.slutload.com/
https://hightimes.com/
https://eu.detroitnews.com/
https://us.pg.com/
https://www.citibank.com.hk/portal/home_english/hkcb_Home.htm
https://distrowatch.com/
https://www.7meiju.com/
https://www.jornaldenegocios.pt/
https://infogram.com/
https://tvseriesfinale.com/
https://d-addicts.com/
https://www.pricespider.com/
https://jornalf8.net/
https://www.komando.com/
https://www.rushlimbaugh.com/
https://www.saveur.com/
https://affinitweet.com/
https://justpaste.it/
https://yaoota.com/en-eg/
https://maverickbyloganpaul.com/
https://www.showbiz411.com/
https://instinctmagazine.com/
https://www.vntrip.vn/
https://www.aftoo.com/
https://www.dcode.fr/
https://itop-gear.ru/
http://www.vpgame.com/
https://www.bangkokpost.com/
https://wn.com/
https://www.rds.ca/
https://androidina.net/
http://xtapes.to/
https://www.humboldt.edu/
http://orcz.com/Main_Page
https://shahiid-anime.net/
https://blog.spoongraphics.co.uk/
https://www.aha.io/
https://www.primecurves.com/
https://freebeacon.com/
https://www.autostraddle.com/
https://www.bankalfalah.com/
https://www.maxthon.cn/
https://www.dinheirovivo.pt/
https://karger.com/
https://www.urlaubspiraten.de/
https://www.yogajournal.com/
https://hypeddit.com/
https://oncoursesystems.com/
https://www.csu.edu.au/
https://www.hrs.de/
https://www.marketingprofs.com/
https://petrovich.ru/
https://www.scania.com/
https://trackitonline.ru/
https://hackaday.io/
https://japanization.org/
https://hypotheses.org/
https://1000projects.org/
http://www.javgay.com/
https://exploratorium.edu/
https://www.miniusa.com/
https://www.abor.com/
https://kyliecosmetics.com/en-gb
http://drunkenstepfather.com/
http://topfiveforex.com/
http://majav.org/
http://tingroom.com/
https://www.ngpvan.com/
https://hired.com/
https://refinancegold.com/
http://marketagent.com/
https://titantv.com/Default.aspx?r=t
https://www.law360.com/
https://subs.ro/subtitrari/
https://www.mlspin.com/
https://www.tvfanatic.com/
https://my.1password.com/
https://firstround.com/
https://blindgossip.com/
http://k-streaming.com/
https://www.lanebryant.com/verify?url=aHR0cHM6Ly93d3cubGFuZWJyeWFudC5jb20vb24vZGVtYW5kd2FyZS5zdG9yZS9TaXRlcy1MYW5lQnJ5YW50LVNpdGU%3D&frame=1692258705935
https://www.graphicsfuel.com/
https://www.comedy.co.uk/
https://www.worldtimeserver.com/
https://www.canardpc.com/
https://medicalmatters.com/
http://www.gebi1.com/
https://www.gismeteo.com/
https://www.servethehome.com/
http://www.imagepost.com/
https://grabien.com/
https://www.fullhdxxx.com/
https://www.keepersecurity.com/
https://www.amateurcommunity.com/
https://golf.com/
https://www.gocar.gr/
https://1password.com/
https://promokodus.com/
https://www.sobaka.ru/
https://dumskaya.net/
https://www.hustler.com/
https://womensecret.com/es/es
https://limametti.com/
https://nastroyvse.ru/
https://meishubao.com/
http://windows8facile.fr/
https://torontolife.com/
http://pornhd8k.me/
https://how2play.pl/
https://megabox.co.kr/
http://thatpervert.com/
https://www.marisa.com.br/
http://commonsta.com/
https://www.whistlerblackcomb.com/
https://www.orange.ma/
https://www.mimibazar.cz/
http://www.allyoulike.com/
http://what-when-how.com/
https://www.shogakukan.co.jp/
https://www.mtholyoke.edu/
https://www.readersdigest.in//
https://www.sexart.com/
http://www.bunnylust.com/
https://www.rendez-vous.ru/
https://www.achievers.com/gb/
https://www.goalcast.com/
https://www.secretescapes.de/
https://speechnotes.co/
https://teddyfeed.com/
https://iprice.ph/
https://www.progress.com/
https://www.lelo.com/
https://www.springlane.de/
http://www.123haitao.com/
https://www.curvyerotic.com/
https://www.worldcubeassociation.org/
https://www.kanzenshuu.com/
http://www.popoholic.com/
https://www.folhabv.com.br/
https://www.neatorama.com/
https://crowdtangle.com/
https://hackmd.io/
https://www.luochenzhimu.com/
https://www.fiat.com.br/
https://www.softheon.com/
https://justanotherpanel.com/
http://coinlib.io/
https://screencrush.com/
https://serbonline.in/SERB/HomePage
https://explore.crystalcommerce.com/
https://www.wrappixel.com/
https://www.instantprint.co.uk/
https://gamehag.com/
https://kincir.com/
https://scaledagileframework.com/
https://mangahelpers.com/
https://www.cricketcountry.com/
http://www.billionwallet.com/
https://www.eastbaytimes.com/
https://www.bestmovie.it/
https://sierracollege.edu/
https://makeupandbeauty.com/
https://www.digitaldjtips.com/
https://lamebook.com/
https://open.fm/
https://kdramastars1.wordpress.com/
https://danieldefo.ru/
http://health-diet.ru/
https://www.weather2umbrella.com/
https://www.bantenprov.go.id/home
https://www.uema.br/
https://www.bizbuysell.com/
https://www.architectsjournal.co.uk/
https://www.teksavvy.com/
https://billypenn.com/
https://www.bpostbanque.be/
https://lloydspharmacy.com/
https://www.payism.biz/
https://www.tiffany.cn/
https://www.sexykittenporn.com/
https://contently.com/
https://fashionbank.ru/
https://longreads.com/
https://www.akcniceny.cz/
https://www.thepeoplehistory.com/
https://www.lucasentertainment.com/
https://www.hurriyetdailynews.com/
https://www.desigual.com/en_GB/
http://release-series.com/
https://www.firstshowing.net/
http://tuwan.com/
https://www.libris.ro/
https://www.financialsamurai.com/
http://thesaker.is/
http://www.taktemp.com/
https://www.systweak.com/
https://www.easel.ly/
https://kstp.com/
https://karigezima.com/
https://www.seyredelim.com/
https://hamyareweb.co/
https://7figuremembers.com/
https://chicagoreader.com/
https://jolse.com/
http://riveraveblues.com/
http://www.btmeiju.com/
https://aish.com/
https://popxo.com/
https://www.metartx.com/
https://www.nationalgeographic.fr/
http://sexindianvideos.com/
https://www.foreo.com/
https://www.thelifeerotic.com/
https://slatestarcodex.com/
https://level.travel/
https://ngrok.com/
https://blog.gtwang.org/
https://orgoglionerd.it/
https://www.veteranstoday.com/
https://cihnet.co.ma/
https://www.midianews.com.br/
http://steve-jansen.github.io/
https://www.nicabm.com/
http://chomanga.org/
http://caacnews.com.cn/
https://www5.sefaz.mt.gov.br/
https://www.audible.fr/
https://www.nekomeowmeow.com/
https://www.needgayporn.com/
https://www.circulaires.com/
https://theinnercircle.co/
https://diaroapp.com/
https://public.websteronline.com/
https://ezzatkhah.com/
http://www.hdgames.net/
https://mathalino.com/
https://www.retrogames.cz/
https://qanvast.com/sg
https://gahar.ir/
https://www.sanicare.de/
https://theupsstore.com/
https://www.rylskyart.com/
https://hotdeals360.com/
https://soloboys.tv/
https://www.3aw.com.au/
https://www.libri.hu/
http://lady5.jp/
https://www.stevenspass.com/
https://gymvirtual.com/
https://www.defenseone.com/
https://desygner.com/
https://www.boxlunch.com/homepage
http://www.grrlpowercomic.com/
https://www.kentonline.co.uk/
https://www.informs.org/
https://popgasa.com/
https://www.paulcraigroberts.org/
http://embedy.me/
https://www.pny.com/
https://www.riopreto.sp.gov.br/
https://www.activenews.ro/
https://www.wcax.com/
https://hearthgamers.com/
https://allani.pl/
https://www.icbc.com.ar/personas
https://www.theburn.com/
https://sunmag.me/
https://www.palmas.to.gov.br/
https://sitenable.pw/
https://www.messynessychic.com/
https://enduro-mtb.com/
https://hentairock.com/
http://mtgwiki.com/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8
https://nogaminopan.com/
https://newsday.co.tt/
https://wiki.mabinogiworld.com/view/Wiki_Home
https://www.educacao.ma.gov.br/
https://www.troc-velo.com/fr-fr
https://www.amyporterfield.com/
https://metalrock.org/
http://callingtaiwan.com.tw/
https://litreactor.com/
https://www.medias-presse.info/
https://luckycosmetics.ru/
https://www.policyx.com/
http://www.wangpanzhijia.net/
https://www.ancient-code.com/
https://representclo.com/
https://www.cpapracticeadvisor.com/
https://www.booklistonline.com/
http://www.wakingtimes.com/
https://somafm.com/
https://www.madthumbs.com/
https://www.blackmoreops.com/
https://www.childsplayclothing.co.uk/
https://www.productionhub.com/
https://www.dejurka.ru/
https://spectator.org/
https://www.storagenewsletter.com/
https://samsforum.com/
http://iamafoodblog.com/
https://www.secretsales.com/
https://www.shabanali.com/
https://www.okemo.com/
https://www.textlocal.in/
https://www.hungryhowies.com/
http://topfile.tj/
https://www.helpingwritersbecomeauthors.com/
https://krebsonsecurity.com/
https://www.spoon-tamago.com/
https://dailyreckoning.com/
https://www.prosiebenmaxx.de/
https://www.nextgov.com/
https://bemanicn.com/
https://stuffyoushouldknow.com/
https://www.nh-hotels.com/en
http://pinkylip.net/
https://tubularlabs.com/
https://www.priceblink.com/
https://www.dainese.com/gb/en/
https://www.spoonflower.com/
https://www.bjjee.com/
https://www.leadforensics.com/
https://www.thebeaverton.com/
https://myspringfield.com/es/es
https://hackspirit.com/
https://www.behr.com/consumer/
http://saude.sp.gov.br/
https://www.insidehook.com/
https://fermilon.ru/
https://www.breckenridge.com/
https://ou.ac.lk/
http://tradcatknight.blogspot.com/
https://alexgyver.ru/
https://www.bit4id.com/
http://teens.net/
https://tradezone.com.br/
https://www.esl.org/
https://remezcla.com/
https://www.nongit.com/
https://elasticsearch.cn/
https://www.aigan.co.jp/
https://www.hive.co.uk/
https://rspb.org.uk/
https://www.panduit.co.jp/
http://motto.net.ua/
https://www.vivthomas.com/
https://ru.tv/
https://eng-entrance.com/
https://kenko-syoku.net/
https://www.webcartop.jp/
https://www.rugbydump.com/
https://graphtreon.com/
https://bestoftheyear.in/
https://www.lemediatv.fr/
https://waynedupree.com/
https://simpsonswiki.com/wiki/Main_Page
https://www.flashflashrevolution.com/
https://www.conforama.pt/
https://unipampa.edu.br/portal/
https://www.inspiremore.com/
https://www.parkcitymountain.com/
https://iprice.my/
https://www.kyushuandtokyo.org/
https://acaai.org/
https://gematrinator.com/
https://www.seduc.pi.gov.br/
https://thelawofattraction.com/
https://thecooperreview.com/
https://www.hibob.com/
https://www.metro.net/
https://www.makemoneydirectories.com/
https://thememove.com/
https://www.conexaolusofona.org/
https://www.islammessage.com/
http://www.etomesto.ru/
https://www.bestpianoclass.com/
https://runthetrap.com/
https://www.jeju.go.kr/index.htm
https://bbtv.com/
https://ddmf.eu/
https://www.sgtreport.com/
https://www.gulfood.com/
https://www.fieb.org.br/
https://www.midflorida.com/
https://www.itespresso.fr/
https://ve.traetelo.com/
https://faperoni.com/
https://www.generation-game.com/
https://www.utalca.cl/
https://www.onrpg.com/
https://www.cowetaschools.org/
https://www.airsoftgi.com/
https://www.kitchenaidafrica.com/
https://www.takimag.com/
https://picovico.com/blog/
https://www.glossy.co/
http://pornplanner.com/
https://www.historicmysteries.com/
https://dakar92.com/
https://queenhairinc.com/
https://www.partyfiesta.com/
https://amfostacolo.ro/
https://www.vogue.com.au/
http://ccmixter.org/
https://www.guitarhabits.com/
https://www.impressivewebs.com/
https://millercenter.org/
https://www.jemogfix.dk/
https://waysidesolutions.com/
https://photorumors.com/
https://artikala.com/
https://www.desnivel.com/
https://ddos-guard.net/en
https://aliholic.com/
https://cryptopp.com/
https://www.izzetmtgnews.com/
https://wp-simplicity.com/
https://www.magicfreebiesuk.co.uk/
https://www.allaboutcareers.com/
https://crazy-net.com/
https://www.joelonsoftware.com/
https://www.errotica-archives.com/
https://rnfiservices.com/
http://scriptshadow.net/
https://www.berge-meer.de/
https://www.2oceansvibe.com/
https://noteabley.com/?utm_source=main
https://leicarumors.com/
https://giovoss.com/
http://todayinterest.com/
https://www.epicpass.com/
https://playporngames.com/
http://alofokemusic.net/
http://karinto.in/
https://medicaregranny.com/
https://smmlite.com/
https://www.commitstrip.com/en/?
https://vincheckpro.com/
https://pomelofashion.com/global/en/
http://lestoilesheroiques.fr/
https://medknsltant.com/
https://www.stylekorean.com/
https://sleepopolis.com/
http://url-shortener.me/
https://postsecret.com/
https://wnyt.com/
https://allaboutthetea.com/
https://www.skiheavenly.com/
https://omegle.webcam/
http://finguide.info/
https://www.mdm-complect.ru/
http://greatdeals.com.sg/
http://factaholics.com/
https://www.pornozinhos.com/
https://pegi.info/
https://onetimesecret.com/
https://iamalpham.com/
https://www.bunddler.com/
https://www.registrocivil.gob.ec/
https://www.telenor.com/
https://beautynetkorea.com/
https://pt.org.br/
http://asked.kr/
https://new.artsmia.org/
https://scp-wiki.wikidot.com/
https://www.drakesoftware.com/
https://magicmadhouse.co.uk/
https://www.ukraine.com.ua/uk/
https://www.lowellsun.com/
https://therationalmale.com/
https://www.auntyflo.com/
http://rikudou.ru/
http://vse-gdz.info/
https://healthimpactnews.com/
https://www.keystoneresort.com/
https://www.theawl.com/
https://obscurasoft.com/
http://ansible.com.cn/
http://loverouge.com.au/
https://stevemorse.org/
https://gtihandbook.com/
https://thisis50.com/
https://www.folger.edu/
https://wire.com/en/
https://www.canon.pt/
https://hi10anime.com/
https://www.ebizautos.com/
http://popcornnowis.blogspot.com/
http://opanoticias.com/
https://computerinfo.ru/
http://myduckisdead.org/
https://eyefakes.com/
https://sonichu.com/cwcki
http://www.bestfree.ru/
https://mysislovesme.com/
https://uni-pannon.hu/
http://www.rotoscopers.com/
https://www.autoalert.com/
https://fnmnl.tv/
http://funmanga.com/
https://autoflowering-cannabis.com/
https://www.kirkwood.com/
https://alidropship.com/
https://fiftyflowers.com/
https://danlimerick.wordpress.com/
https://premiumcoding.com/
https://s-ul.eu/
https://www.ibiza-spotlight.com/
https://www.andreearaicu.ro/
https://chatous.com/
https://www.sugardaddymeet.com/
https://koreantrick.com/
https://naturalhealthresponse.com/
https://www.themanual.com/
http://tlgrm.eu/
https://www.raywhite.com/
https://www.leosims.com/
https://www.joker.com.tr/
https://uepb.edu.br/
https://www.dropsend.com/
https://www.hcm-cityguide.com/
https://hirohitorigoto.info/
https://moonpower2020.net/
https://www.holley.com/
https://mytaboo.net/
https://www.kinointeres.ru/
https://www.dungeonworldsrd.com/
https://www.bodymeasurements.org/
https://www.addiction-beauty.com/
https://www.voltaredonda.rj.gov.br/
https://clubsnap.com/
https://www.domai.com/
https://nfhslearn.com/
https://www.experatoo.com/
https://famousinyourfield.com/
http://www.funny-quotes-life.com/
http://www.jukujyo-collection.com/
http://blakmusicfirst.fr/
https://ricochet.media/en
https://www.alphabetagamer.com/
https://www.eschoolnews.com/
https://tamigo.com/
https://gleamplay.com/
https://www.contributors.ro/
https://www.scrapebox.com/
https://www.bnconline.com/
https://www.lens.org/
https://www.socialads.eu/
https://www.iefp.pt/
https://www.intervieweb.it/hrm/
https://www.elektrobit.com/
http://turbogvideos.com/
https://www.westgateresorts.com/
https://bnamericas.com/
https://www.bucadibeppo.com/
https://www.entertainmentbox.com/
https://www.crikey.com.au/
https://globalrose.com/
https://guildnews.de/
https://sleeknote.com/
https://nlo-mir.ru/
https://www.loa.org/
https://www.fastcar.co.uk/
https://afriquefemme.com/fr/
https://www.babyclub.de/
https://tapnewswire.com/
https://www.bikereg.com/
https://pythonconquerstheuniverse.wordpress.com/
https://stephenking.com/
https://williamspaniel.com/
http://www.porncomics.me/
https://faqeo.com/
https://www.vail.com/
https://courtneygallert.wordpress.com/
https://jabuzz.jp/login
https://www.ohgaki.net/
https://www.poboke.com/
https://www.vainglorygame.com/
http://gardrops.com/
https://www.parkme.com/accounts/login/?next=/
http://awgp.org/
https://www.estekhdami.org/
https://cutedeadguys.net/
https://www.rdnews.com.br/
https://smartclassroommanagement.com/
https://aeoneshop.com/
https://forextradingstrategies4u.com/
https://www.qbn.com/
https://www.miseria.com.br/
https://www.belldirect.com.au/smarter/
http://bancoamazonia.com.br/
http://www.irandooble.com/
http://chp.com.ua/
https://luandaoportunidades.wordpress.com/
https://www.norma24.de/
https://www.barcelonaturisme.com/wv3/en/
https://www.profm.ro/
https://www.world-mysteries.com/
https://watchdocumentaries.com/
https://www.theholocaustexplained.org/
http://ielts-academic.com/
https://comicsalliance.com/
https://www.jackdaniels.com/
http://gdrivedownload.us/
https://egeriya.ru/
https://dinnerqueen.net/
https://citizenfreepress.com/
http://rosettedelacroix.com/
https://youngsexhd.net/
https://www.needforseat.de/
https://tasteofcountry.com/
https://www.todoinstagram.com/
https://apeoc.org.br/
https://www.prestwickhouse.com/
https://cers.com.br/
https://fr.meetic.be/
https://www.tiffany.ca/choose-your-language/
https://piotrminkowski.wordpress.com/
https://www.awardsdaily.com/
https://leangains.com/
https://virginradio.ro/
https://kiszamolo.hu/
https://www.northstarcalifornia.com/
http://yapx.ru/
https://www.reviewgeek.com/
https://www.aliva.de/
https://www.conservapedia.com/Main_Page
https://www.amateurcommunity.de/
https://www.matecat.com/
https://hellobeautiful.com/
https://www.creative-writing-now.com/
https://www.empireofthekop.com/
https://ddowiki.com/
https://www.kla.tv/en
https://rankeopty.com/
https://www.rtrs.tv/
https://www.bpplas.com/
https://www.pixelatedgamer.com/
https://www.rabbitsreviews.com/
https://www.myfairtrade.com/
https://www.funded.today/
https://firenewsfeed.com/
http://modernrock.ru/
https://www.accusoft.com/
https://www.whats-your-sign.com/
https://www.extole.com/
https://www.filmous.com/
https://porngamesgo.com/
https://www.rhdjapan.com/
http://twinktube.sexy/
https://benjaminfulfordcastellano.wordpress.com/
https://edi.wang/
https://hqsbonline.wordpress.com/
http://english-now.jp/
http://gabiyori.com/
https://warashibe76.com/
https://ygfamilylover.wordpress.com/
https://www.olybet.lv/
https://pedrodelhierro.com/es/es
https://www.ceara.gov.br/
http://www.hcrealms.com/
https://bnf.gov.py/
https://eushtiu.com/
http://ipod-touch-max.ru/
https://eztv.yt/
https://www.naughtyhentai.com/
https://www.onespace.com/
https://www.fucsia.co/
https://www.watchtime.com/
https://www.bookpage.com/
https://asiansexdiary.com/
https://360yield.com/login
http://freepdfbook.com/
https://profittask.com/
http://summerswipe.com/
https://www.campogrande.ms.gov.br/
http://pikastar.com/
https://literary-devices.com/
https://thebridgebk.com/
https://www.olybet.ee/
https://blog.darkthread.net/
https://zerocarbzen.com/
https://steveblank.com/
https://excitemii.com/
https://effortlessenglishclub.com/
https://www.centreofexcellence.com/
https://www.fiat.com.ar/
https://www.bicotender.ru/
https://www.arbeitsschutz-express.de/
https://likegrowers.com/
https://nanokino.net/
https://unusual-design.ru/
https://www.greenheartgames.com/
https://www.netzkino.de/
https://maggianos.com/
http://creamoff.ru/
https://www.gaoshouvr.com/
https://jarneil.wordpress.com/
https://www.jiluhome.cn/
https://masteradmissions.com/
https://www.mgzxzs.com/
http://motuowei.com/
http://qinxuye.me/
https://ridingtheelephant.wordpress.com/
https://silveredtongue.wordpress.com/
https://teemtry.com/
https://www.visit-gloucestershire.co.uk/
https://game4v.com/
http://braindamaged.fr/
https://www.feelingsurf.fr/
https://www.mattmorris.com/
https://www.vitalbmx.com/
https://www.deepwebsiteslinks.com/
https://consortiumnews.com/
https://www.payback.mx/
https://www.lawgazette.co.uk/
https://www.alefo.de/forum/
https://characterdesignreferences.com/
https://redash.io/
https://www.khwiki.com/
https://gobages.com/
https://www.a-contresens.net/
https://www.vapeototal.net/
https://www.1ka.si/d/sl
https://www.wsaz.com/
https://fzmovies.xyz/
https://www.infosnutrition.fr/
https://www.netgsm.com.tr/
http://uokufa.edu.iq/
https://www.bondsuits.com/
https://www.lovesac.com/
https://www.thesecret.tv/
https://www.busybudgeter.com/
https://www.writerswrite.co.za/
http://nudevoyeursex.com/
https://www.bluecorona.com/
https://cerego.com/browser/upgrade
http://thedigitaltheater.com/
https://www.articleforge.com/
https://www.testingmom.com/
https://www.edelweiss.plus/
https://www.ciheam.org/
https://www.mediaevent.de/
https://spherebeingalliance.com/
https://passioncrypto.com/
https://sexflashgame.org/
https://runnersconnect.net/
https://show-english.com/
https://www.gamespassport.com/
https://www.metartnetwork.com/
https://www.prettycosmetics.ru/
https://www.ucraft.com/
http://sakeritalia.it/
https://cruft.io/
https://www.igroved.ru/
http://www.thefinertimes.com/
https://www.optikseis.com/
https://www.chacos.com/US/en/home
https://comunidadeculturaearte.com/
https://t-b.ru.com/
https://hungrybuffs.com/some/boulder/delivery/featured
http://www.ronpaulforums.com/content.php?s=790ef743ef761be88af2a8e66dd78289
https://freeenglishlessonplans.com/
https://www.jauce.com/
http://comicspro.ru/
https://www.altronix.pt/
https://coroinhasdelondrina.wordpress.com/
https://gdpackaging.wordpress.com/
https://radioangola.org/
https://seminariogospel.com/
http://www.sopterj.com.br/
http://torhiddenwiki.com/
http://www.dangerandplay.com/
https://parsmovies.net/
https://www.skimag.com/
https://www.bloggingbasics101.com/
http://find-music.net/
http://www.pi.gov.br/
https://parcelsapp.com/
https://cantuse.wordpress.com/
https://insper.edu.br/
https://www.portaldoservidor.ma.gov.br/
https://www.sloganseller.com/
https://tonyortega.org/
https://gatesofvienna.net/
https://selfpackaging.es/
http://staseve.eu/
https://www.dijitalajanslar.com/
https://jstuff.wordpress.com/
https://www.foodservicedirect.com/
https://wealthresult.com/
https://www.kondom.it/
http://23promocodes.com/
https://www.mimicmethod.com/
https://oddle.me/
https://www.stunning18.com/
https://www.luxstyle.pk/
https://exiledrebelsscanlations.com/
https://www.alldaychemist.com/
https://30lines.com/
https://www.forexchief.com/
http://theglitterguide.com/
https://www.mercantile.co.il/MB/private/
https://www.geekzone.fr/
https://www.brennancenter.org/
http://suchisoft.com/
https://avtozam.com/
https://howtolucid.com/
https://tadtopmail.com/
http://marveltoynews.com/
https://booksrun.com/
https://www.kbs.gov.my/
https://www.creativetemplate.net/
http://giftcardspromocodes.com/
https://leadershipfreak.blog/
http://digitalaltitude.co/
https://www.scummvm.org/
https://insolentiae.com/
https://20jack.com/
https://wng.org/
https://www.naiin.com/
https://mastersofscale.com/
https://www.oakleyforum.com/
https://www.launchrock.com/
https://video-nvidia.com/
http://instabuilder.com/v2.0/launch/
https://www.tvsoap.it/
https://keetonsonline.wordpress.com/
https://www.segep.ma.gov.br/
https://faroldenoticias.com.br/
https://theonyxpath.com/
https://cassiopaea.org/
https://www.belfercenter.org/
https://anemone.dodgson.org/
https://www.macstories.net/
https://threatpost.com/
https://22dakika.org/
https://www.snow.com/
https://0120656889.net/
https://0systems.com/
https://adbaji.com/
https://ailovei.com/
https://alee-beach.jp/
https://amatou-papa.com/
https://anajal-mileage.com/
https://answer-mama.com/
https://arupakahaha.com/
http://b-masters.com/
https://bbs-joyful.net/
https://chester-souzoku.com/
http://cloudibee.com/
https://cost-zero.com/
http://creatorjapan.asia/
https://www.crypto-currency.news/
https://digrajapan.org/
https://doyouevenblog.com/
http://egokororoman.com/
https://eitopi.com/
https://www.encounter-pedia.com/
http://feticomx.com/
http://finance-gfp.com/
https://fromsite.info/
http://hajimete-tousi.com/
https://hyip-information.com/
http://iku-share.jp/
http://ikumen-smile.com/
https://japan-trip.cn/
https://www.japanarts.co.jp/
http://jforexmaster.com/
https://ji-ko.jp/
https://jinjamemo.com/
https://kabu-daytrade.com/
http://www.kanichat.com/
https://kmode.info/
http://www.kokusyo.jp/
http://www.kosodatedou.co
one nation :: underground